
Cross Validation & Hyperparameter
교차검증, 하이퍼파라미터 예제코드를 통한 개념 이해
교차검증(Cross Validation)
- 모델 학습 시 데이터를 훈련용과 검증용으로 교차하자
- 이유 : 과적합 방지
- Train / Validation / Test
- Train : 학습 셋
- Validation : 검증 셋
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_validate
# 데이터 셋
wine = pd.read_csv('https://bit.ly/wine_csv_data')
# input / target 1차 분리
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
# train / valid / test 분리
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42
)
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42
)
# 모형 만들고 평가 - valid데이터 평가
dt = DecisionTreeClassifier(random_state = 42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))
#0.9971133028626413
#0.864423076923077
print(dt.score(test_input, test_target))
#0.8569230769230769
# 교차검증
scores = cross_validate(dt, train_input, train_target)
print(scores)
#{'fit_time': array([0.0121038 , 0.01054382, 0.01129436, 0.01120663, 0.01073456]),
#'score_time': array([0.00164652, 0.00206113, 0.00140262, 0.00141835, 0.00147724]),
#'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}
scores['test_score'] # -> 샘플링 결과가 편향되어있기 때문에 값의 차이가 다 다르다
#array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])
# 검증 데이터 score(테스트데이터 score)
np.mean(scores['test_score'])
# 0.855300214703487
층화추출
- 기존 의 임의 추출 방식(무작위)은 데이터가 편향적임
- 새로운 방법 : StratfiedkFold 활용
- 데이터를 분리 할때 덜 편향적으로 섞이게 하자
- 통계용어 : 층화추출 (비율에 근거해서 추출하기)
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target, cv = StratifiedKFold())
np.mean(scores['test_score'])
#0.855300214703487
# n_splits : 몇번 교차 검증을 할건지
splitter = StratifiedKFold(n_splits = 10, shuffle = True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv = splitter)
np.mean(scores['test_score'])
#0.8574181117533719
하이퍼파라미터(Hyperparameter)
- 모델링할때 사용자가 파라미터를 직접 세팅하여 모델이 성능을 향상시킴
그리드 서치(Gird Search)
- 기존 코드) 수동으로 조정, 하나씩 값을 확인하는 형태
- ridge(), Lasso(), alpha값 조정
- decision tree, max_depth값 조정
- 현재) 파라미터 조정 자동화 –> 머신러닝 엔지니어가 할 일
- https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
# 모형 만들기
dt = DecisionTreeClassifier(random_state = 42)
# 하이퍼 파라미터
params = {'max_depth' : [2,3,4,5,6,7]}
gs = GridSearchCV(dt, params, n_jobs=-1)
# 모형 학습 --> params의 인자의 개수만큼 수행
gs.fit(train_input, train_target)
# 가장 최적화된 max_depth 확인
print(gs.best_params_)
#{'max_depth': 5}
best_dt = gs.best_estimator_
print(best_dt.score(train_input, train_target))
#0.8672310948624207
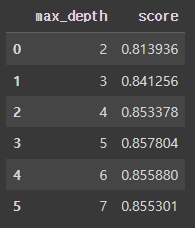
# 데이터 프레임으로 가시화
gs.cv_results_['mean_test_score']
result = pd.DataFrame({
'max_depth' : [2,3,4,5,6,7],
'score' : gs.cv_results_['mean_test_score']
})
result
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
# 여러 하이퍼파라미터 전달
params = {'max_depth' : [2,3,4,5,6,7],
# min_impurity_decrease : 노드 분할 시, 불순도 감소 최저량 지정
'min_impurity_decrease' : np.arange(0.0001, 0.001, 0.01),
'min_samples_split' : range(2, 100, 10)
}
gs = GridSearchCV(dt, params, n_jobs=-1)
gs.fit(train_input, train_target)
# 최적의 파라미터
print(gs.best_params_)
# {'max_depth': 7, 'min_impurity_decrease': 0.0001, 'min_samples_split': 92}
# 최적의 결과
best_dt = gs.best_estimator_
print(best_dt.score(train_input, train_target))
# 0.8793534731575909
랜덤 서치(Random Search)
- 그리드 서치는 여러 하이퍼파라미터 전달
- 랜덤 서치는 매개변수가 샘플링할 수 있는 객체의 범위를 전달 - 랜덤 파라미터
from scipy.stats import uniform, randint # 랜덤 실수, 정수
from sklearn.model_selection import RandomizedSearchCV
import numpy as np
# 랜덤 파라미터
params = {'max_depth' : randint(2,50),
'min_impurity_decrease' : uniform(0.0001, 0.1),
'min_samples_split' : randint(2,50)
}
# 모형 만들기
dt = DecisionTreeClassifier(random_state = 42)
# 랜덤 서치
rs = RandomizedSearchCV(dt, params, n_iter = 100 , random_state = 42 ,n_jobs = -1)
rs.fit(train_input, train_target)
# 최적의 파라미터
print(rs.best_params_)
# {'max_depth': 39, 'min_impurity_decrease': 0.00017787658410143285,
# 'min_samples_split': 22}
# 최적의 결과
best_dt = rs.best_estimator_
print(best_dt.score(train_input, train_target))
# 0.9053299980758129
Leave a comment