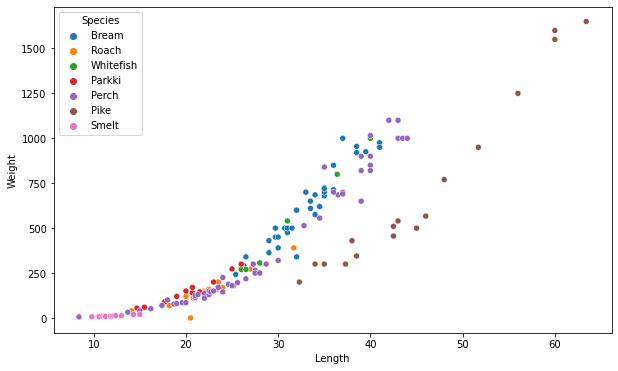
위 데이터셋과 같이 특성이 많으면, KNN 모델로는 특성 간의 관계나 디테일한 확률을 알기 힘들다
로지스틱 회귀는 특성 간의 관계를 보여주고 특정 결과의 확률을 계산한다
Logistic Regression
여러 특성(이벤트)가 있을 경우 확률을 결정하는 데 사용되는 통계 모델
로지스틱 회귀 맛보기
확률값 구하기
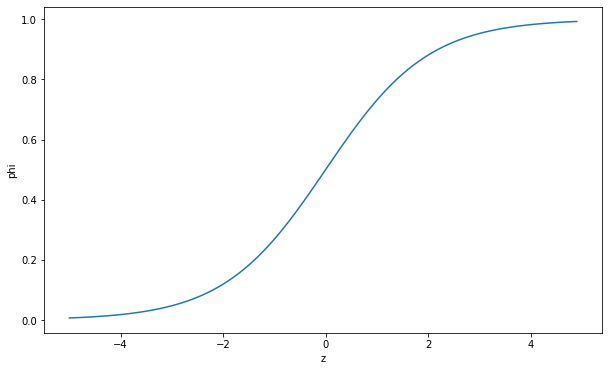
z 값 구하기
시그모이드 함수에 z값 대입 -> 확률값 계산
확률값이 매우 큰 음수 –> 0
확률값이 매우 큰 양수 –> 1
importmatplotlib.pyplotasplt#인위로 z값 설정
z=np.arange(-5,5,0.1)# 시그모이드 함수
phi=1/(1+np.exp(-z))#시각화
fig,ax=plt.subplots(figsize=(10,6))ax.plot(z,phi)ax.set_xlabel('z')ax.set_ylabel('phi')plt.show()
로지스틱 회귀로 이진 분류 수행하기
현재 데이터 : train_scaled & test_scaled
현재 데이터에는 물고기들의 이름이 없기 때문에
train_target, test_target과 Boolean Indexing 수행
Boolean Indexing : True, False 값을 활용함
fromsklearn.linear_modelimportLogisticRegressionfromscipy.specialimportexpit# 주어진 데이터 Boolean indexing
bream_smelt_indexes=(train_target=='Bream')|(train_target=='Smelt')bream_smelt_indexes#new data
train_bream_smelt=train_scaled[bream_smelt_indexes]target_bream_smelt=train_target[bream_smelt_indexes]train_bream_smelt.shape,target_bream_smelt.shape# ((33, 5), (33,))
lr=LogisticRegression()lr.fit(train_bream_smelt,target_bream_smelt)#z값 함수
decisions=lr.decision_function(train_bream_smelt[:5])print(decisions)# [-6.02927744 3.57123907 -5.26568906 -4.24321775 -6.0607117 ]
#시그모이드 함수
print(expit(decisions))# [0.00240145 0.97264817 0.00513928 0.01415798 0.00232731]
#로지스틱 회귀로 다중 분류 수행하기
#규제 추가. ridge, lasso의 alpha와 반대개념
lr=LogisticRegression(C=20,max_iter=1000)lr.fit(train_scaled,train_target)print(lr.score(train_scaled,train_target))# 0.9327731092436975
print(lr.score(test_scaled,test_target))# 0.925

Leave a comment