# 라이브러리 설치
!pipinstallopencv-pythonimportcv2importnumpyasnp# 버전확인
print(cv2.__version__)print(np.__version__)# 구글 드라이브 마운트
fromgoogle.colabimportdrivedrive.mount("/content/drive")DATA_PATH='*colab 데이터 폴더 경로*'print(DATA_PATH)
데이터 이해
데이터 살펴보기
%matplotlibinlineimportcv2importnumpyasnpimportmatplotlib.pyplotaspltimg=cv2.imread(DATA_PATH+'/ants/swiss-army-ant.jpg')print(img.shape)# print 결과 : (261, 280, 3)
# 의미 : 이미지의 배열 구성 : 세로값 261, 가로값 280, 컬러 채널 3(R, G, B)
# 이미지 배열 구성 확인
# 세로 사이즈
print(len(img))# 261
# 가로 사이즈
print(len(img[0]))# 280
# 컬러 체널
print(len(img[0][0]))# 3
# 이미지 픽셀 값 확인
# print(img)
# print(img[:3])
plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))plt.show()
데이터 그레이 스케일
그레이 스케일(gray scale) : 채널3(rgb)로 이루어진 데이터를 채널1으로 변환
하는 이유 : 연산 속도와 메모리사용량을 줄이기 위함
# 그레이 스케일
gray_img=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#이미지 사이즈 확인
print(gray_img.shape)# print 결과 : (261, 280)
#이미지 표시
plt.imshow(gray_img,cmap='gray')plt.show()
데이터 이진화
그레이스케일 이미지보다 더 정보를 줄여서 특징량을 돋보이게 함.
픽셀값이 경계값보다 크면 백(255), 작으면 흑(0)으로 주어 흑백 이미지로 변환 : 이미지 임계처리
# 이미지 폴더 지정
importosimportcv2importnumpyasnpimportpandasaspd# 이미지 폴더 지정
dirs=['ants','bees']# 이미지의 픽셀값과 레이블을 보전하기 위한 리스트 생성
pixels=[]# 설명변수
labels=[]# 목적변수
fori,dinenumerate(dirs):# 파일명을 취득
files=os.listdir(DATA_PATH+'/'+d)forfinfiles:# 이미지를 그레이 스케일로 READ
img=cv2.imread(DATA_PATH+'/'+d+'/'+f,0)# 이미지 리사이징
img=cv2.resize(img,(128,128))# 픽셀값을 보전
img=np.array(img).flatten().tolist()pixels.append(img)# 이미지의 Label을 리스트에 보존
labels.append(i)# 픽셀값을 데이터 프레임 형식으로 변환
pixels_df=pd.DataFrame(pixels)pixels_df=pixels_df/255# 정규화
# Label을 데이터 프레임 형식으로 변환
labels_df=pd.DataFrame(labels)labels_df=labels_df.rename(columns={0:'label'})# 2개의 데이터 프레임을 수평결합
img_set=pd.concat([pixels_df,labels_df],axis=1)img_set.head()
모폴로지 변환
모폴로지(Morphology) 기법
홀 채우기, 잡음 제거 등 이진화 과정에서 발생하는 불명확한 물체 영역을 명확하게 함
압축, 팽창, 오프닝, 클로징 등의 처리를 함
압축(Erosion)
이미지의 필터를 슬라이드하면서 필터의 픽셀값을 정리
필터의 픽셀값이 전부 1(백)일 경우에만 1, 그렇지 않은 경우 0 출력
객체의 돌출부를 제거하는데 유용
배경 노이즈를 제거하는데 유용
객체 내부 노이즈는 확대시키는 단점이 존재
# 이미지 불러오기
img=cv2.imread(DATA_PATH+'/ants/swiss-army-ant.jpg',0)# 이진화 이미지로 변환
ret,bin_img=cv2.threshold(img,128,255,cv2.THRESH_BINARY)# 이미지 압축
kernel=np.ones((3,3),np.uint8)# (3*3) : 필터 크기 / np.uint8 : 데이터타입
img_el=cv2.erode(bin_img,kernel,iterations=1)# 필터 kernel를 적용하고 압축
plt.imshow(img_el,cmap='gray')
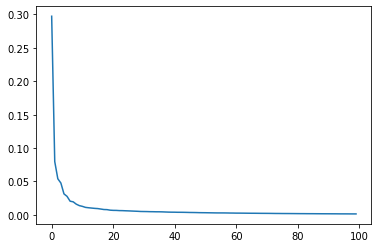
fromsklearn.decompositionimportPCA# 주성분분석의 누적 기여율 95%까지 추출하겠다
pca=PCA(0.95)pixels_pca=pca.fit_transform(pixels_df)# 주성분 확인
print(pca.n_components_)plt.plot(pca.explained_variance_ratio_)plt.show()# PCA를 적용한 설명변수와 목적변수 결합
img_set_pca=pd.concat([pd.DataFrame(pixels_pca),labels_df],axis=1)img_set_pca.head()
# PCA적용 전후 이미지
# 적용 전
plt.imshow(np.array(pixels_df)[4].reshape(128,128),cmap='gray')plt.show()# 적용 후 복원
pixels_low=pca.inverse_transform(pixels_pca)plt.imshow(pixels_low[4].reshape(128,128),cmap='gray')plt.show()









Leave a comment